
ModLauncher
7D2D Mod Launcher

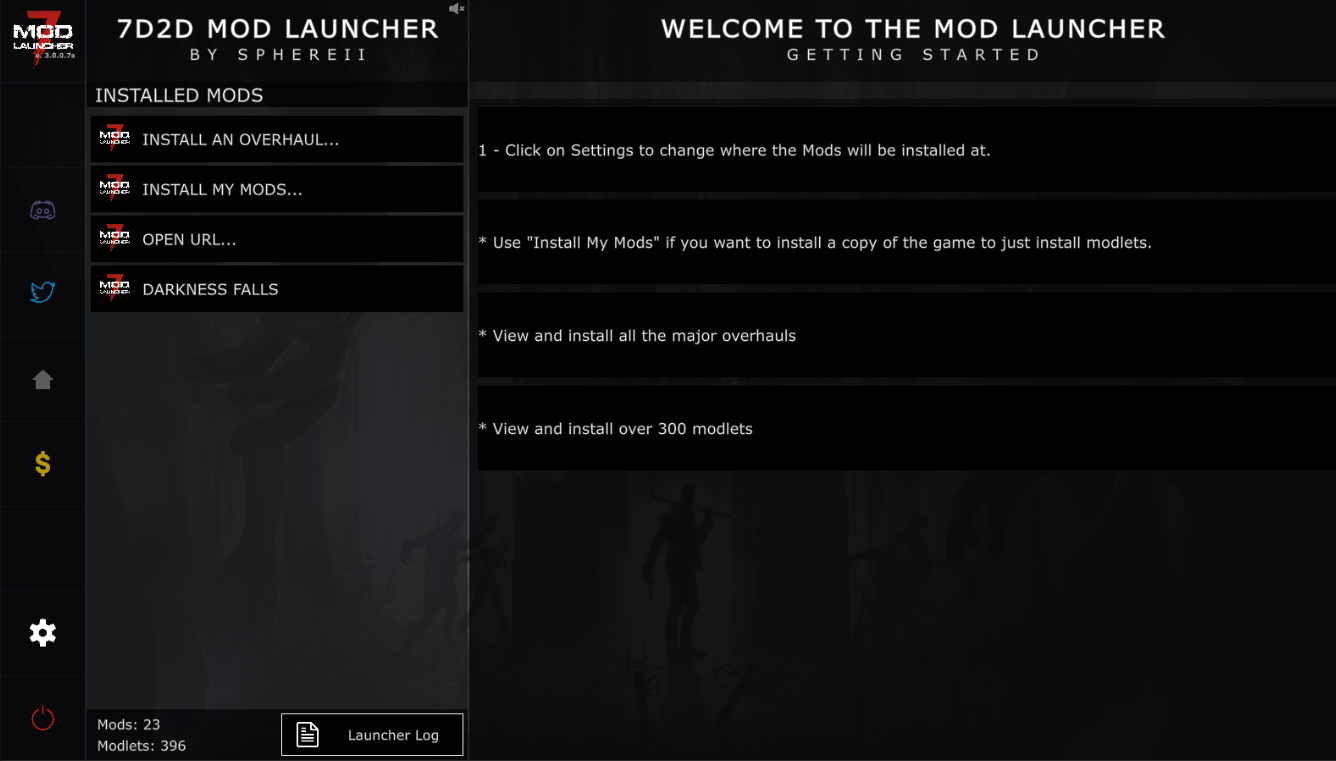
The 7D2D Mod launcher gives an easier method to play your favourite modifications for 7 Days to Die, while keeping them updated automatically for you. It also gives a simple method to explore and locate new modifications.
The latest incarnation of the Mod Launcher is V5, created using Unity UI ToolKit with the purpose of being interoperable with Linux, MacOS, and Windows. Currently, only Linux and Windows is known to operate, whereas MacOS is extremely theoretical today.
Project's Discord
Support Email: Support@7D2DModLauncher.org
Want to donate? PayPal
Technical Changes in V5
-
Git implementation was removed because it was causing problems with larger mods' stability.
-
Finds Overhauls and Modlet versions and download links using the git API.
-
The UI ToolKit for Unity 2021.
-
HTTP downloads that use a custom class to show download progress are implemented.
-
Remove the download of UnityWebRequest because it was causing instability problems.
-
Utilizes a Windows installer for InnoSetup.
-
Windows Installer / Uninstaller with digital signature.
Features
-
Find and download a ton of updates, and keep them current with the newest releases.
-
Keep multiple copies of the same mod and switch between them for various saves and worlds.
-
Go back and look at previous Alphas' mods.
-
Locate and set up more than 300 modlets for each Alpha.
-
Easily integrate third-party modlets from websites like Nexus Mods and 7 Days To Die Mods.
-
You can personalize your vanilla experience by creating "My Mods," a blank overhaul.
-
Automatic snapshots taken each time you play, serving as built-in backups for generated worlds and saves.
-
Operates in offline mode by default; no data is fetched upon startup.
-
Installer/UnInstaller (only for Windows)
Review
7 Days to Die ModLauncher is a popular tool among the game's community, offering a straightforward and efficient way to manage, install, and play various mods for the survival horror game "7 Days to Die."
User Interface and Ease of Use
The ModLauncher boasts a user-friendly interface, making it accessible even for those not tech-savvy. Its clean and intuitive design allows players to easily navigate through different mods, read descriptions, and see key information.
Mod Variety and Accessibility
One of the ModLauncher's strongest points is the extensive variety of mods it hosts. From simple tweaks to complete gameplay overhauls, it caters to a wide range of preferences.
Installation and Compatibility
The installation process of the ModLauncher is straightforward. It seamlessly integrates with the base game, minimizing conflicts and compatibility issues.
Performance and Stability
In terms of performance, the ModLauncher does an excellent job. It runs smoothly, with minimal lag or crashes.
Community and Support
The ModLauncher is backed by a strong community. There's a sense of shared enthusiasm and support, with active forums and discussions where players can exchange tips and share experiences.
Pros
-
User-friendly interface.
-
Wide variety of mods.
-
Easy installation and mod management.
-
Stable performance with minimal issues.
-
Strong community support.
Cons
-
Might be overwhelming for first-time modders due to the number of available mods.
-
Some mods may require additional steps or configurations not immediately apparent to new users.
The 7 Days to Die ModLauncher is an excellent tool for both seasoned modders and newcomers. Its user-friendly interface, variety of mods, and stable performance make it a top choice for enhancing the 7 Days to Die experience.
Legacy Mod Launcher

The 7D2D Mod launcher (by SphereII - a modder and developer) provides an effortless way to manage your favourite mods for 7 Days to Die, while keeping them updated automatically for you. Mod launcher also provides an easy way to explore and finds new mods. Mod launcher is essentially software that installs, upgrades, and runs 7D2D mods.
Many of the latest mods are supported, and you can keep it up to date without having to visit the forums.
In addition to certain default mods that you may already be familiar with, the 7D2D Mod Launcher includes a number of Valmar's excellent mods such as Expansion and Overhaul, CHS and Horde, and mods such as A Clockwork Project, Spider's True Survival mod, and TheRedWolf's SteelMod.
Additionally, in addition to playing the individual modifications, you can also play combination mods, which would consist of a standard mod combined with a prefab kit, such as one from stallionsden's Megacity or Magoli's ComoPack, respectively.
Some of the most thrilling and captivating aspects of using this mod launcher are that it separates mod installations (which prevents conflicts with overhauls, automatically updates the launcher, and enables players to even customize overhauls using an integrated modiet management method.
Before attempting to use an overhaul such as Gnamod, Ravenhearst, or War3zuk, players must first install 7D2D Mod Launcher.
A new clean, bare minimum website to help you find exactly what you want, quickly and easily.
Download
Requirements
-
Microsoft .NET Framework 4.6.1 (x86 and x64)
-
Internet connection at the time of use (offline version is under development)
Features
-
Discover and install new mods easily and quickly
-
Keeps your mod installations separate; avoid potential conflicts with over hauls
-
Automatically updates itself to the latest version
-
Automatically updates the mods each time you play, while also giving you the option
to keep playing on your existing version
- Allows you to customize even overhauls, using the integrated Modlet Management Tool
What does it do, exactly?
Simply put, the Launcher reads a remote 7D2D configuration file containing various download links
to the various mods. When you want to play a mod, you select it from the list, and it will
download and install the mod for you before launching the game.
You can also create your own configuration, known as My Mods, by mixing and matching
mods as you see fit.
If you're playing on a server, your server administrator can create a config for the Launcher
to use that includes all of their required download links. Do you require the back pack mod?
The Server Administrator can include it in their zip file, and everyone will have access to it.
The 7D2D Mod Launcher comes with some default mods that you may already be familiar with,
including Valmar's great mods, including Expansion, Overhaul, CHS, and Horde, as well as
mods such as A Clockwork Project, Spider's True Survival mod, and TheRedWolf's SteelMod.
In addition to playing the individual mods, you can also play combination mods, which would be
a regular mod, plus a prefab kit, either from stallionsden's Megacity or Magoli's ComoPack.
The 7D2D Launcher provides an effortless way to play your favorite mods for 7 Days To Die
Automatically updates to the most recent versions of the mods from the servers you've chosen.
Sets the server address in your Connect to Server window automatically.
Connect to various servers while using various mods.
Supporting My Mods in order to expand the player base for mods
For Server Administrators
The 7D2D Launcher provides a single file configuration that lets you specify your download links,
website, and other information. By providing that file to your players, they will keep up to
date with all your changes that you do, without having to hunt down forum posts.
The 7D2D Launcher allows you to specify your download links, website, and other information in
a single file configuration. By providing that file to your players, they will be able to keep
up with all of your changes without having to search for forum posts.
A straightforward XML file configuration that lists all of your servers and download links.
Use a service provider li to centralize the link.ke Text Uploader.
The 7D2DLauncher will load the new version.
For Modders
The 7D2D Launcher gives you a larger player base to test your mods on.
Your players will be able to play your mods with ease if you create your own XML
configuration file or simply provide direct download links.
My Mods
My Mods is a concept that allows players to deploy mods from the 7 Days to Die modding
community for single player instances. Modders can reach a larger player base and provide
a more consistent format by adhering to the My Mods Standard.
How to Install 7 Days To Die Mod Launcher for Darkness Falls & Ravenhurst
-
exit the mod installer
-
delete the c:\7D2D folder (or wherever you have it installed)
-
launch the mod launcher and install the Fun Pimps latest stable build
-
then install the Darkness Falls mod
-
then Pre-Synch the mod.
The mod installer will create a new c:\7D2D folder with a clean install of 18.3 for
the DF mod to use. My old Fun Pimps version was likely the problem and I needed
a clean install to refresh something to give me my text back. Just make sure you
have green checkboxes besides the Fun Pimps latest stable and besides
Darkness Falls before you synch the mod and run it.
7 Days to Die Mod Launcher, The seven days to die mod launcher is an efficient way to play and update
your game on a regular basis. It is an absolute necessity that you update the items.
You will also receive messages from the game informing you of new updates.
7D2D contains numerous elements such as mods, maps, weapons, tricks, locations, and many more.
Then, while playing, you must install a mod launcher. This launcher is extremely simple to set up.
To begin, you may encounter some difficulties while downloading. Here is a step-by-step guide to
using and downloading the launcher for your convenience.
The launcher box will include many mods, such as the power mod and the fear steel mod.
So, whether you go with one mod or another is entirely up to you.
Then, before downloading 7 days 2 die launcher, you must create multiple folders.
There are also alphas such as alpha 16, alpha 17, alpha 18, and alpha 19. As a result,
you can go for an alpha that you are currently playing. Furthermore, it can be an exciting
time for you.
Most importantly, survival SDX last time is also available for users for improved interaction.
EAC, on the other hand, is intended for users who are not connected to the internet.
As a result, if you are an offline user, you do not need EAC.
Throughout the process, keep your vanilla folder separate from any existing 7D2D folders.
Copy your launcher into the box, then hit play. As a result, the launching system will be
displayed. CA must be turned off later. Finally, run and save as default.
How to check consistency
Right-click on 7 days to die from the Steam library to open its properties.
Click the Local Files tab, then click Check Game File Consistency.
Repeat until you succeed.
Another great tutorial by Ztensity (or as HTML).
Nitrogen | KingGen | KingGen| KingGen Service | Seeds
Want to play and use mods? Go ahead and rent a server.
